HTTP Streams in Node.js
Learn how to efficiently transfer data over HTTP using Node.js streams, including handling backpressure, error management, and memory optimization best practices.
When transferring data to clients—whether it’s an HTML file or a large ZIP archive—Streams offer significant advantages. By streaming data, we can begin transmission while content is still being generated, rather than waiting to load the entire file into memory. This approach not only conserves server resources but also provides a faster experience for clients.
In this guide, you’ll learn:
- How to implement basic HTTP streaming in Node.js
- Proper error handling strategies for streams
- How to manage backpressure effectively
- Best practices for memory optimization
Table of Contents
Understanding Streams
To illustrate how streams work we can create a simple HTTP server using Node.js HTTP module:
// src/01-stream-example.js
import http from "node:http";
const server = http.createServer((req, res) => {
res.writeHead(200, { "Content-Type": "text/plain" });
setImmediate(() => {
res.write("Hello");
setImmediate(() => {
res.write("World");
res.end();
});
});
});
server.listen(8080, () => {
console.log("listening on http://localhost:8080");
});The server callback receives two parameters req (request) and res (response). We can say that req is a readable stream from which we can read, and res is a writable stream to which we can write. In practice this is a bit more nuanced but lets keep it simple for demonstration purposes.
Boot the server and try it out using cURL:
curl --trace trace.txt http://localhost:8080You will notice that two packets where received, one for each time we wrote to the response stream:
<= Recv data, 10 bytes (0xa)
0000: 35 0d 0a 48 65 6c 6c 6f 0d 0a 5..Hello..
<= Recv data, 15 bytes (0xf)
0000: 35 0d 0a 57 6f 72 6c 64 0d 0a 30 0d 0a 0d 0a 5..World..0....Now try it out without using setImmediate:
import http from "node:http";
const server = http.createServer((req, res) => {
res.writeHead(200, { "Content-Type": "text/plain" });
res.write("Hello");
res.write("World");
});
server.listen(8080, () => {
console.log("listening on http://localhost:8080");
});Notice how in this case we only get one packet:
<= Recv data, 20 bytes (0x14)
0000: 35 0d 0a 48 65 6c 6c 6f 0d 0a 35 0d 0a 57 6f 72 5..Hello..5..Wor
0010: 6c 64 0d 0a ld..This is because writing data to the socket occurs after the current call stack has cleared.
Extending the previous snippet we can easily create a function that sends data in chunks to the client. Just write to the response stream as data is being generated.
In practice there are two caveats.
Error Handling
Headers must be written before the body—once you perform the first write operation, you cannot modify them. This limitation stems from the structure of an HTTP message. As a result, if your process fails after beginning transmission, you cannot inform the client by changing the response Status.
This will result in a ERR_HTTP_HEADERS_SENT error:
res.writeHead(200, { "Content-Type": "text/plain" });
try {
res.write("Hello");
throw new Error("o_O");
res.write("World");
} catch (err) {
res.setHeader("Status", 500);
} finally {
res.end();
}How you work around this depends on your use case. The following snippet illustrates how you could try rendering a page by first sending the head with all the links and resource hints so the browser can start fetching them and then send the actual page content.
res.writeHead(200, { "Content-Type": "text/html" });
res.write(pageHead);
try {
retry(async () => res.write(await getPageBody(req)), {
times: 3,
timeout: 1000,
});
} catch (err) {
res.write(errorBody);
} finally {
res.end();
}On other cases such as a PDF download there is not much you could do to fail gracefully and then the client will end up with a corrupted file. To mitigate that you could provide an endpoint to report the download status so the client can provide feedback to the user.
Backpressure
There is a Spanish humorist that popularized the phrase “Chickens in, chickens out”. In an ideal scenario our client will read data at the same rate as we are generating it, therefore data in, data out. Chickens rule holds true. But what happens if the server generates data faster than the client can consume it?
In this case Node.js will start buffering data, which will start causing trouble, potentially ending up crashing the application due to memory exhaustion. This problem is known as Backpressure.
Demonstrating backpressure
In order to illustrate what happens when we get more data that we can send, we will generate binary data at a rate of 20MB/s and send it over to a client accepting 10MB/s. We will do this for 20 seconds and analyze the memory usage of the application using Clinic.js Doctor.
First we will start by creating a function to generate chunks of data:
const chunkSize = 20 * 1024 * 1024; // 20MB
const chunkGenerationTime = 1000; // 1s
function createChunk() {
return new Promise((resolve) => {
setTimeout(
resolve,
chunkGenerationTime,
new Uint8Array(new ArrayBuffer(chunkSize)),
);
});
}And then we will use it to send data over to the client:
// 02-backpressure.js
const server = http.createServer(async (req, res) => {
res.writeHead(200, { "Content-Type": "application/octet-stream" });
let chunk = 0;
const totalChunks = 20;
while (chunk < totalChunks) {
chunk++;
console.log("\nWriting chunk", chunk);
res.write(await createChunk());
}
res.end();
});
server.listen(8080, () => {
console.log("listening on http://localhost:8080");
});In order to test it we will use curl’s --rate-limit option. Make sure to dump the output using --output nul in Windows or --output /dev/null in Unix systems:
curl --output /dev/null --limit-rate 10M http://localhost:8080Run that command and you will see how the client is receiving data much after the server stopped generating it.
Lets run it with Clinic.js now (if you are using PowerShell quote the two hyphens before node, ’—’):
clinic doctor --on-port 'curl --output /dev/null --limit-rate 10M http://localhost:8080' -- node src/02-backpressure.jsInspect the memory usage chart and you will notice how the RSS (Resident Set Size), where buffers are stored, grows over 200MB.
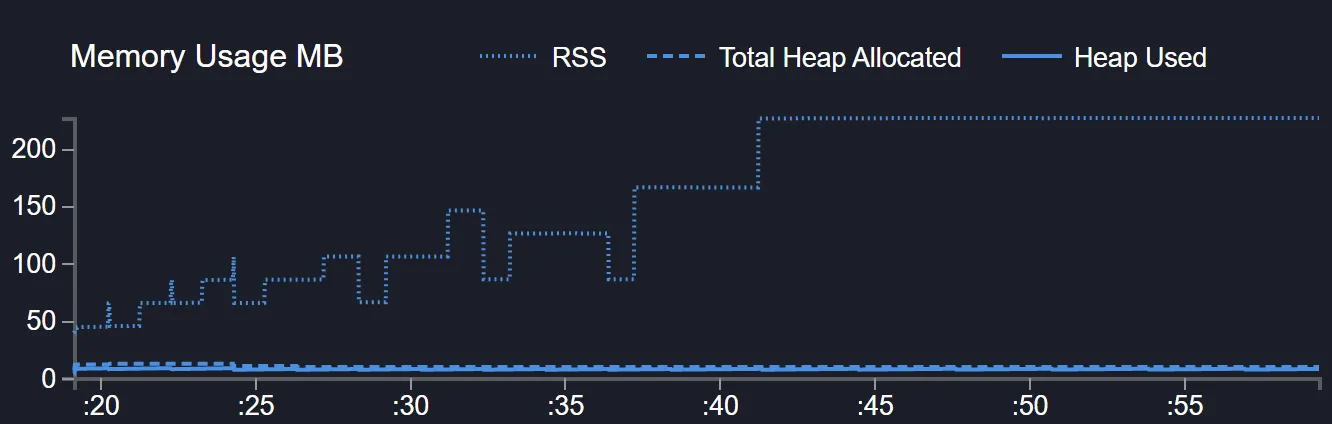
Waiting for the client
As demonstrated above, we cannot just keep writing data to a client that won’t accept it without increasing the application memory consumption until it eventually crashes. Node.js streams provide a neat mechanism to avoid that. Calling write() will return a boolean indicating wether the client can admit more chunks or not. If data has been queued and the buffer is full, it will also emit a drain event once we are able to start writing again.
Having this into account, we can modify the above example to:
- Stop writing data once
write()returnsfalseand - Wait for the
drainevent to fire before resuming operations.
// src/03-using-drain.js
const server = http.createServer(async (req, res) => {
res.writeHead(200, { "Content-Type": "application/octet-stream" });
let chunk = 0;
const totalChunks = 20;
while (chunk < totalChunks) {
chunk++;
console.log("\nWriting chunk", chunk);
const canKeepWriting = res.write(await createChunk());
if (!canKeepWriting) {
await new Promise((resolve) => res.once("drain", resolve));
}
}
res.end();
});This time the memory usage is much better, hovering around 80MB.
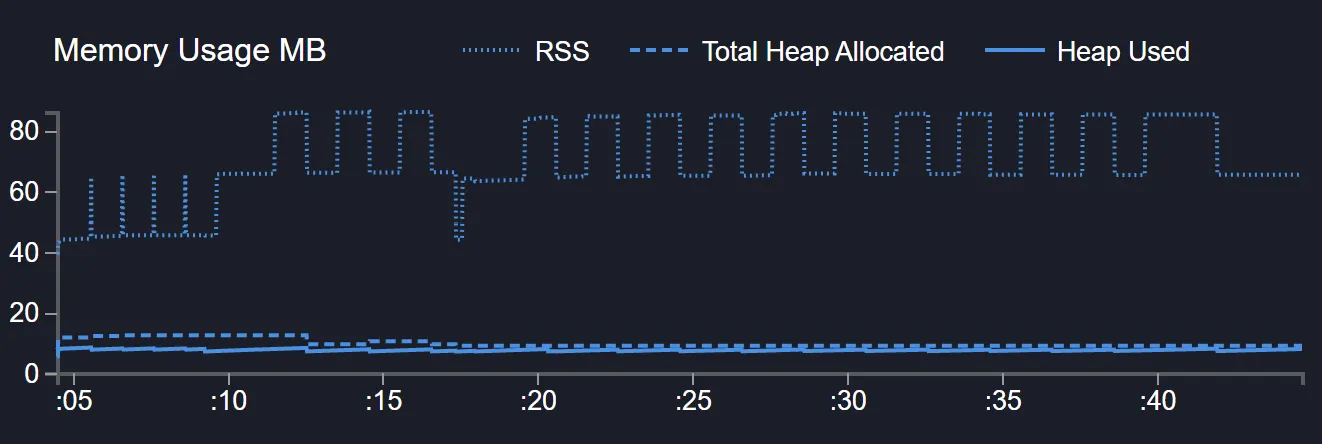
Handling backpressure in readable streams
We could implement a readable stream in order to generate our data. It is enough with extending from Readable and implementing the _read() method:
import { Readable } from "node:stream";
const totalChunks = 20;
class CustomReadableStream extends Readable {
constructor(opts) {
super(opts);
this._chunk = 0;
}
async _read() {
while (this._chunk < totalChunks) {
this._chunk++;
console.log("\nWriting chunk", this._chunk);
const canKeepWriting = this.push(await createChunk());
if (!canKeepWriting) {
return;
}
}
this.push(null);
}
}When the stream is created nothing happens, the stream has no consumer so it will not generate data. As soon as someone starts reading from it, for example by adding a data listener, it will go into flowing mode, calling _read() in order to produce data.
We will keep calling push() with the generated chunks until it returns false, signaling that no additional chunks should be pushed. This will happen when the internal buffer is full.
In order to consume this stream, we will start by listening for the data event and writing back the chunks to the response stream. Once the response wont accept more writes, we will pause() the stream, and once the response buffer is empty and we can keep pushing data again (drain event) we will resume() the stream turning it back into flowing mode:
// src/04-readable.js
const server = http.createServer(async (req, res) => {
res.writeHead(200, { "Content-Type": "application/octet-stream" });
const stream = new CustomReadableStream();
stream.on("data", (chunk) => {
const canKeepWriting = res.write(chunk);
if (!canKeepWriting) {
stream.pause();
res.once("drain", () => stream.resume());
}
});
stream.on("end", () => res.end());
});Memory consumption spikes at first and then becomes stable around 80MB again.
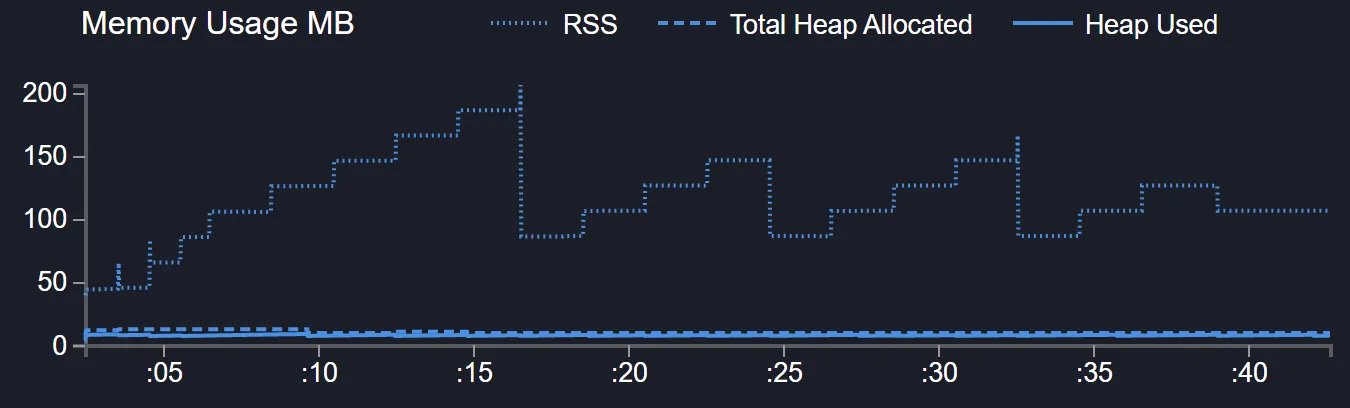
The simple approach
If you have been working with streams for a while without issues and didn’t know about this chances are you have been using pipe() since it handles backpressure for you.
In addition creating streams from generators lets us simplify things one step further:
// src/05-pipe.js
import { Readable } from "node:stream";
function* generateFile() {
const totalChunks = 20;
let chunk = 0;
while (chunk < totalChunks) {
chunk++;
console.log("\nWriting chunk", chunk);
yield createChunk();
}
}
const server = http.createServer(async (req, res) => {
res.writeHead(200, { "Content-Type": "application/octet-stream" });
const stream = Readable.from(generateFile());
stream.pipe(res);
});In this case we can see once again a nice stair shaped memory graph:
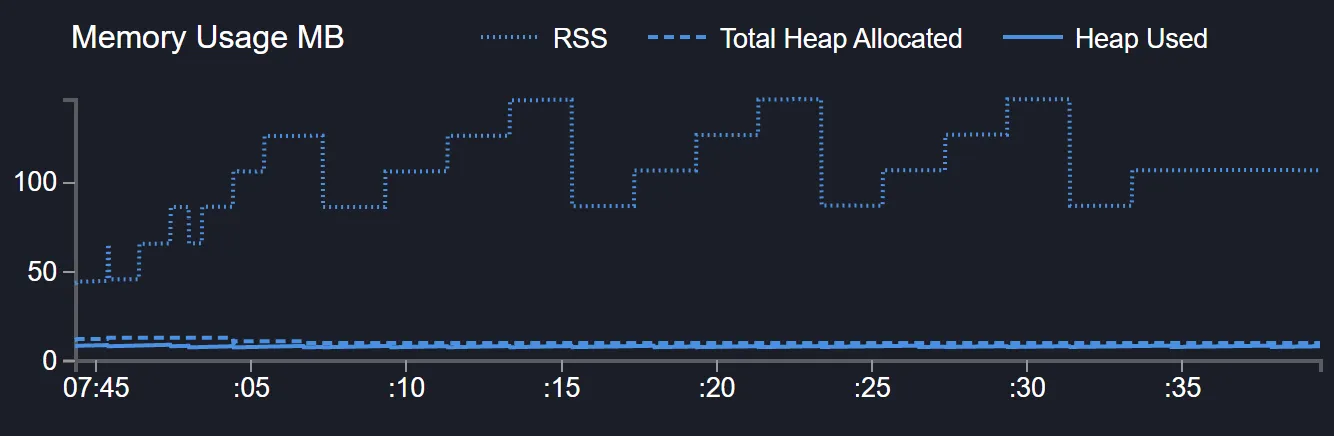
Lets try with more data, maybe 100MB/s (remember our client accepts 10MB/s)
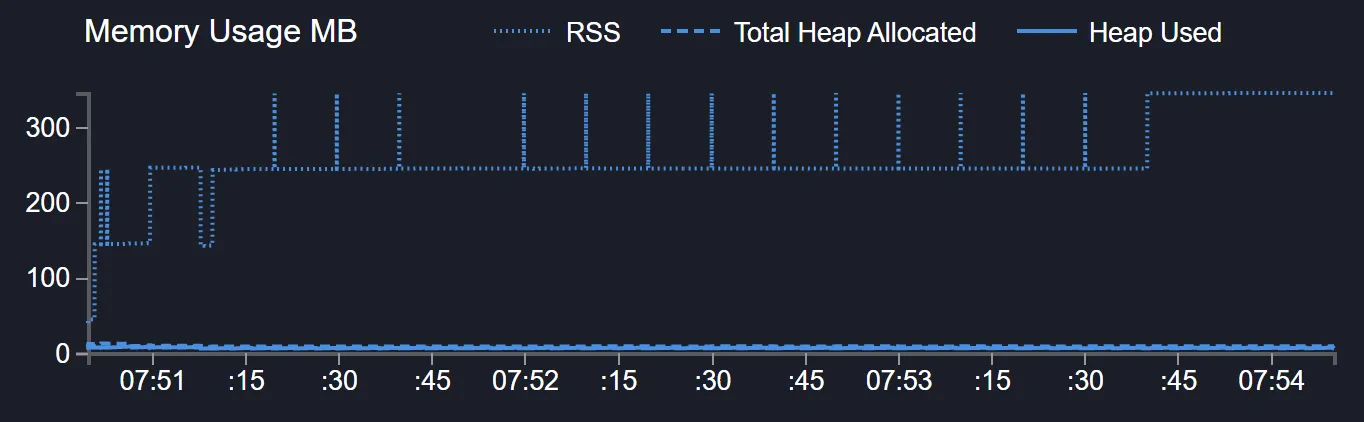
And compare it with the scenario that is not handling backpressure:
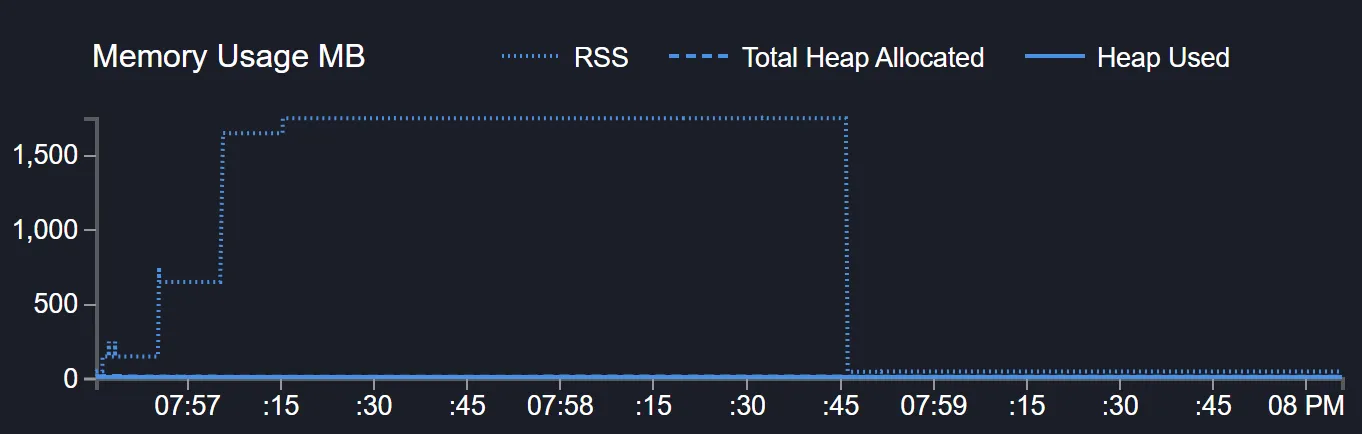
From 1.5GB+ to maybe 400MB peaks? Pretty good.
Key Takeaways
- Use streams wisely: Implement streams to reduce memory usage and improve response time
- Plan for errors: Design error handling strategies appropriate for your use case
- Prefer
pipe(): Use thepipe()method whenever possible for automatic backpressure handling - Consider generators: When writing custom readable streams, leverage generators for cleaner code
- Monitor performance: Use tools like Clinic.js to track your application’s behavior
- Test edge cases: Remember that backpressure isn’t always immediately apparent—test with slow clients
- Configure buffers: Adjust internal stream buffer size using
highWaterMarkwhen needed - Verify third-party streams: When using external readable streams, ensure they handle backpressure properly
- Consider alternatives: For non-pausable data sources, explore options like
Range requests
Sometimes we don’t want to handle backpressure, and instead let slow clients drop packages. For an example implementation, see this leaky stream implementation.
Extra: Can I Pause HTTP Requests?
Yes! You can call pause() and resume() on the response body stream:
// src/06-fetch.js
import fetch from "node-fetch";
fetch("http://localhost:8080").then((response) => {
response.body.on("data", () => {
console.log(`data`);
});
setTimeout(() => {
console.log("pause");
response.body.pause();
}, 1000);
setTimeout(() => {
console.log("resume");
response.body.resume();
}, 20000);
});To analyze how the server reacts in different scenarios, open two terminals and run:
clinic doctor -- node .\src\05-pipe.jsclinic doctor -- node .\src\06-fetch.jsYou’ll observe that the server stops generating chunks while the client is paused. This behavior likely works because TCP/IP has built-in mechanisms to handle backpressure—but use at your own risk!